Introducing media-tsunami: Brand Voice as Executable Code.

media-tsunami — 6 seconds, local Python pipeline, drop-in CLAUDE.md for any LLM.
Most brand voice tools end with a PDF nobody reads, a dashboard nobody opens, or a walled-garden AI that does not plug into your stack. The voice dies on the first handoff.
I wanted to treat brand voice like code instead. A file you can version, diff, share, and plug into any LLM session. So I built it, and today I am open-sourcing it.
media-tsunami
github.com/whystrohm/media-tsunami
Point it at a URL. It reads the site with a local Python pipeline — no LLM calls anywhere in the extraction — computes the statistical signature of the voice, and emits three files:
voice-fingerprint.json— raw signals for debuggingbrand-config.json— machine-readable brand rulesCLAUDE.md— drop-in LLM system prompt
The CLAUDE.md is the output that matters. Load it into Claude, ChatGPT, or any LLM. The model now writes in that brand's voice on the first try. Not a style guide it ignores. Actual constraints: cadence rules, signature vocabulary, forbidden words, exemplar sentences, semantic territory.
The Technical Part That Is Actually Interesting
Voice extraction here is statistics, not LLM judgment. Five steps, all local:
- spaCy sentencizer splits the corpus and computes cadence: mean sentence length, fragment rate, pronoun ratios, punctuation density, question/exclamation rates.
- sentence-transformers (all-MiniLM-L6-v2) embeds every sentence. Take the centroid. The sentences closest to the centroid represent the semantic center of gravity of the voice. Those become your exemplar sentences.
- TF-IDF + k-means cluster the brand's vocabulary into semantic territories.
- Contrast against wikitext-2. Words way more common in the brand corpus than wikitext become signature words. Words common in wikitext but absent from the brand become forbidden words. You are not handing the model a blacklist. You are letting the model discover what the brand refuses to say by measuring what the brand's absence looks like relative to generic English.
- Heuristic tone classifier maps cadence + vocabulary patterns to one of 8 labels (punchy, direct, formal, conversational, analytical, authoritative, energetic, instructive).
The whole thing runs in about 3 seconds on a 15K-word corpus. Zero API calls, zero telemetry, nothing leaves your machine. MiniLM (~80MB) and wikitext-2 (~1MB) cache after first run.
What It Looks Like in Practice
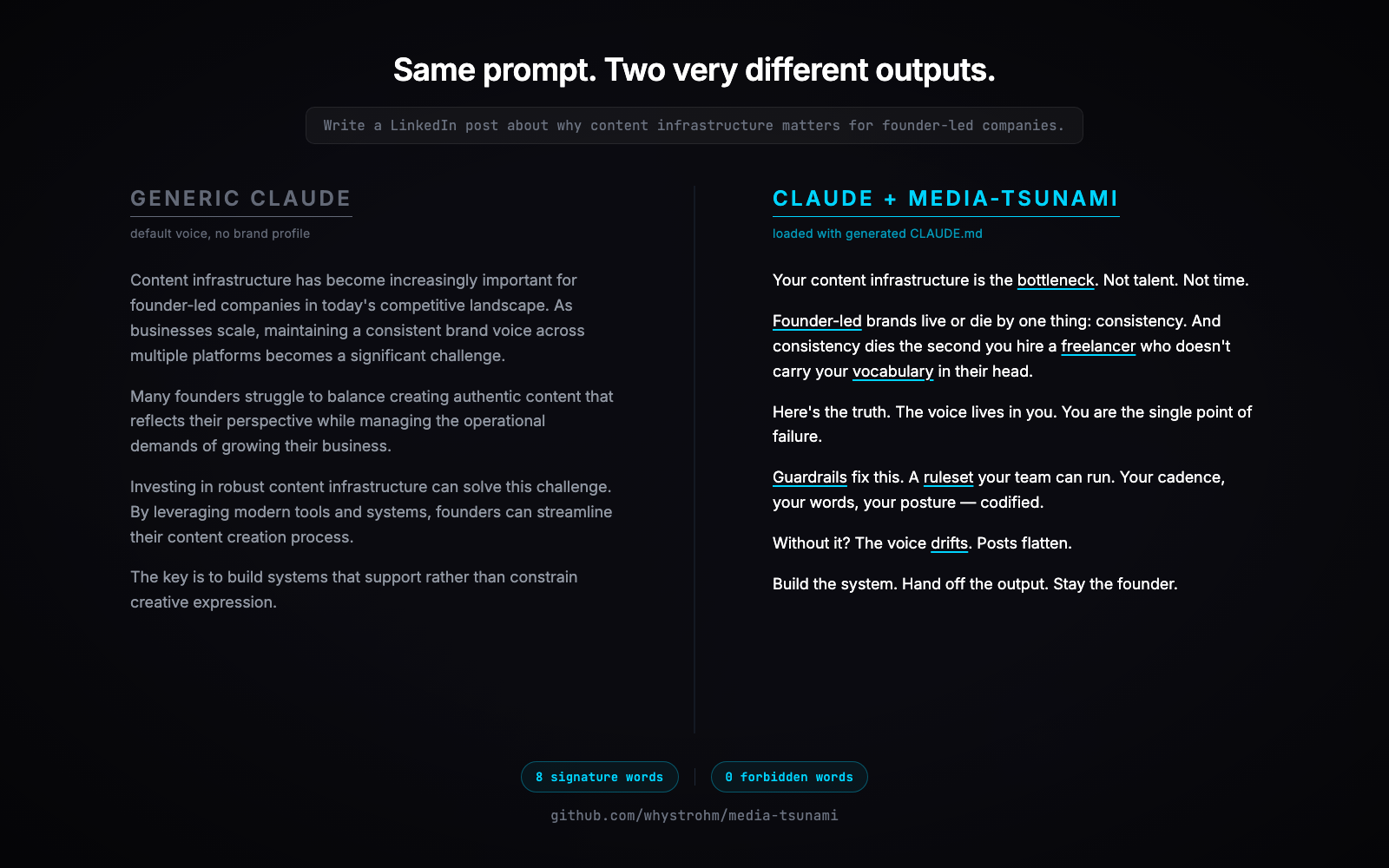
I ran it on my own site. Same prompt, same Claude session, one with the generated CLAUDE.md loaded and one without.
Generic Claude:
Content infrastructure has become increasingly important for founder-led companies in today's competitive landscape. As businesses scale, maintaining a consistent brand voice becomes a significant challenge. Many founders struggle to balance creating authentic content that reflects their perspective while managing the operational demands of growing their business.
Claude with media-tsunami CLAUDE.md loaded:
Your content infrastructure is the bottleneck. Not talent. Not time. Founder-led brands live or die by one thing: consistency. And consistency dies the second you hire a freelancer who doesn't carry your vocabulary in their head. Here's the truth. The voice lives in you. You are the single point of failure.
Same model. Same prompt. The difference is a text file loaded into the session. That is the moat.
The Full Breakdown — What It Actually Extracted
I ran media-tsunami on whystrohm.com. Here is everything it pulled out, field by field, from a 15,262-word corpus across 19 pages.
Corpus Stats
- 19 pages scraped (home, about, /system, /pricing, /scan, 14 blog posts)
- 15,262 words, 1,848 sentences analyzed
- Pipeline runtime: 3.3 seconds
- Zero API calls. Everything runs locally.
Cadence Profile
- Mean sentence length: 8.5 tokens (short. aggressive.)
- Target range: 3–15 tokens per sentence
- Fragment rate: 32% (roughly every third sentence is under 5 tokens)
- Punctuation density: 21 marks per 100 words (punchy, high-rhythm)
- Second-person pronoun ratio: 4.4% (the brand speaks directly to the reader, not about itself)
- First-person ratio: 1.1% (sparingly)
Tone Classification
Primary: punchy. Secondary: direct. Confidence: 100%.
The heuristic tone classifier maps cadence + vocabulary patterns to one of 8 labels. WhyStrohm scored at the top of the "punchy" bucket because all four triggers fired: mean sentence length under 10 tokens, fragment rate above 30%, median sentence under 7 tokens, punctuation density above 15 per 100 words. The classifier prescribes a directive the LLM follows:
"Write punchy. Fragments are fine. One thought per sentence. Hit hard, move on. Blend in direct elements: write with directness, short declarations, skip qualifiers, make the claim."
Signature Vocabulary
These are the words that appear far more often in the WhyStrohm corpus than in a generic English baseline (wikitext-2). Ratios range from 10× to 60× above generic:
guardrails, bottleneck, linkedin, founder-led, brands, ruleset, freelancer, drifts, vocabulary, instagram, carousels, automated, consistency, pipeline, codified
Anyone writing in this voice should reach for these words. They are not a style choice — they are the specific language the brand has shaped around its positioning. The LLM loaded with the CLAUDE.md now treats these as preferred vocabulary.
Forbidden Vocabulary
These are common English words that appear frequently in wikitext-2 but are systematically absent from the brand corpus. Wikipedia-flavored nouns and hedges:
game, song, season, city, series, world, film, however, album, war, early, several, including, known, although
The methodology is not a blacklist. It is a statistical contrast. If a word is common in wikitext-2 and the brand corpus has a near-zero count, the brand is implicitly avoiding it. The LLM is instructed to never use these words and to rephrase if one appears in a draft.
Words like however, although, several, including are the most useful entries on this list — these are hedging and formal-register connectives that the brand has cut out to stay punchy. Those are genuine voice signals. Words like album and war are topical noise (the brand is not about music or history) and the v0.2 semantic filter demotes those further.
Exemplar Sentences
The engine embeds every sentence with MiniLM, computes the corpus centroid, and selects the sentences closest to it. These represent the brand's semantic center of gravity. Six chosen for WhyStrohm:
- "It knows your sentence structure."
- "When your brand voice lives in your head, every piece of content requires you."
- "Voice, visuals, timing — all enforced by the same system."
- "A system that codifies brand voice into guardrails and produces consistent content every time."
- "The system catches words and phrases that violate the brand voice before they go live."
- "This is the one layer most founders actually get right — if they are writing their own copy."
The LLM is told to pattern-match on the rhythm, word choice, and posture of these sentences when generating new output.
A Second Before/After
Not just LinkedIn posts. Here is the same side-by-side on an email follow-up prompt, for good measure.
Prompt: Write a short email following up with a prospect who went silent after a $12K content infrastructure proposal.
Generic Claude:
Hi [Name], I hope this email finds you well! I wanted to follow up on the proposal I sent over a couple of weeks ago. I completely understand how busy things can get, and I just wanted to check in to see if you had any questions or concerns about the proposal. Please let me know if there is anything I can clarify or if you would like to discuss further. I'm happy to jump on a call at your convenience. Looking forward to hearing from you!
Claude with media-tsunami CLAUDE.md loaded:
12 days of silence after a $12K proposal means one of two things: scope mismatch or timing mismatch. Both are fine. Both have a fix. If it is scope, tell me which pieces do not map to what you actually need and I will rebuild the proposal around those. If it is timing, give me a date you want to kick off and I will hold the slot. Either way, you are not ghosting me. You are just not sure how to say what is actually the block. Say it.
Same model. Same prompt. The CLAUDE.md is doing the work.
See the Raw Output
The full generated CLAUDE.md for WhyStrohm is checked into the repo. Read it, fork it, compare it to what you would produce manually: examples/whystrohm-CLAUDE.md.
Why Portable Matters
The output is a text file. Not a model. Not a weight. Not a fine-tune. That means:
- Your voice profile is portable across LLM providers
- It works today on Claude, tomorrow on whatever replaces Claude
- You can diff it, version it, fork it
- You can share it publicly or keep it in a private repo
- No vendor lock-in
Generalizes Beyond Marketing
The pipeline does not know it is extracting "brand voice." It extracts stylistic signal from any text corpus. Which means:
- Extract a support voice from your help docs so customer service bots stay on-brand
- Extract an engineering voice from senior PR descriptions so auto-generated PRs match the team's register
- Extract a compliance voice from legal-approved copy so drafts clear review faster
- Extract one individual's voice from their writing so a true digital twin exists as a prompt
Where It Plugs In
media-tsunami is the empirical ground-truth layer of a stack of tools I have been open-sourcing:
- media-tsunami (new) — extracts voice empirically from any URL
- digital-twin-of-yourself — reverse-engineers a person's voice (how you think, not just how you write)
- voice-extract — quick conversational voice analysis with 15 guardrails
- audit — scores content against a 5-layer framework
- voice-scorer — measures voice drift between site and social
media-tsunami runs once and produces the brand config. The four Claude skills consume that config as their shared reference. When I scale across brands, all five tools agree on what each brand's voice actually is. No drift between tools.
What Is Next
- v0.2 — visual fingerprint. Palette, typography, spacing, composition rules extracted from screenshots.
- v0.3 — motion fingerprint. Shot length, editing rhythm, transition patterns from video.
- v0.4 — hosted brand book. Auto-generated HTML portal from the JSON. A real digital brand guide, not just a system prompt.
- PyPI publish landing this week.
Try It
git clone https://github.com/whystrohm/media-tsunami
cd media-tsunami && pip install -e .
python -m spacy download en_core_web_sm
tsunami --url https://yourbrand.comMIT licensed. 59 tests. GitHub Actions CI across Python 3.11, 3.12, and 3.13. Feedback welcome, especially on brands where the forbidden-word list still has topical noise. Those are the v0.2 tuning cases.
Free in 10 seconds
Find out what's costing you time, trust, and conversions.
The WhyStrohm Content Audit scores your published content against 5 layers of infrastructure-grade standards. Vocabulary. Structure. Proof density. Voice consistency. Buyer alignment. You get a number, the exact quotes that earned it, and a live rewrite of your weakest piece.
Or reach out directly
Tell me about your brand.
Name, email, and one line. I'll get back to you within 24 hours.