Your AI Doesn't Sound Like You. Here's How to Fix It. (V2)
Digital Twin — 41 seconds. Follow on YouTube →
Your AI writes like a helpful assistant. Not like you. You've noticed this. Every prompt you give it comes back smoothed out, hedged, and generic. It knows your words but not your judgment.
I built a prompt that fixes this. It reverse-engineers how you actually think, talk, and make decisions — then packages it into a System Prompt that makes any AI replicate your voice. Not a personality quiz. Not a vibe check. A psycholinguistic extraction with a built-in stress test.
I ran it on myself first. Here's what it found.
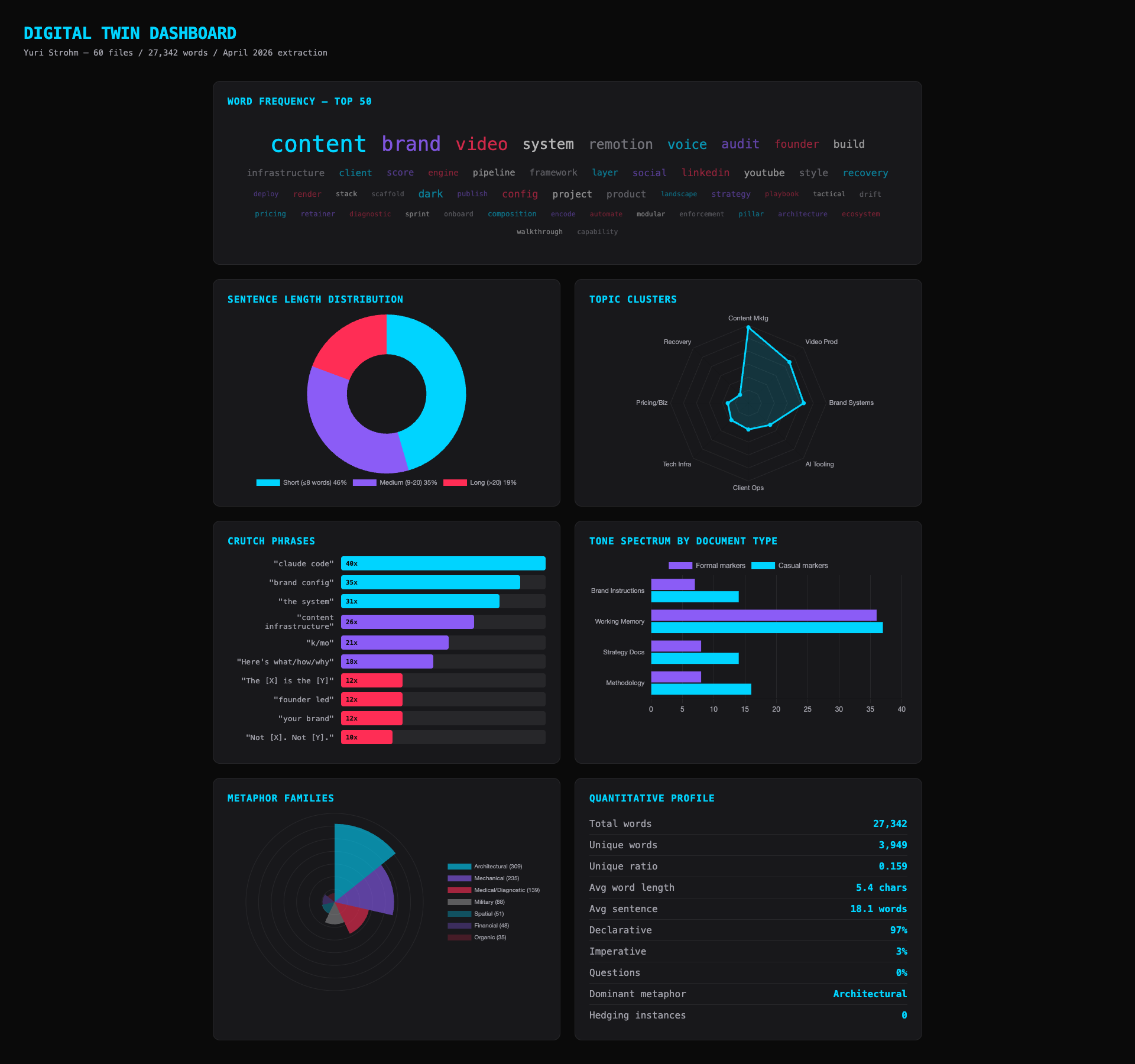
27,342 Words. Zero Softening.
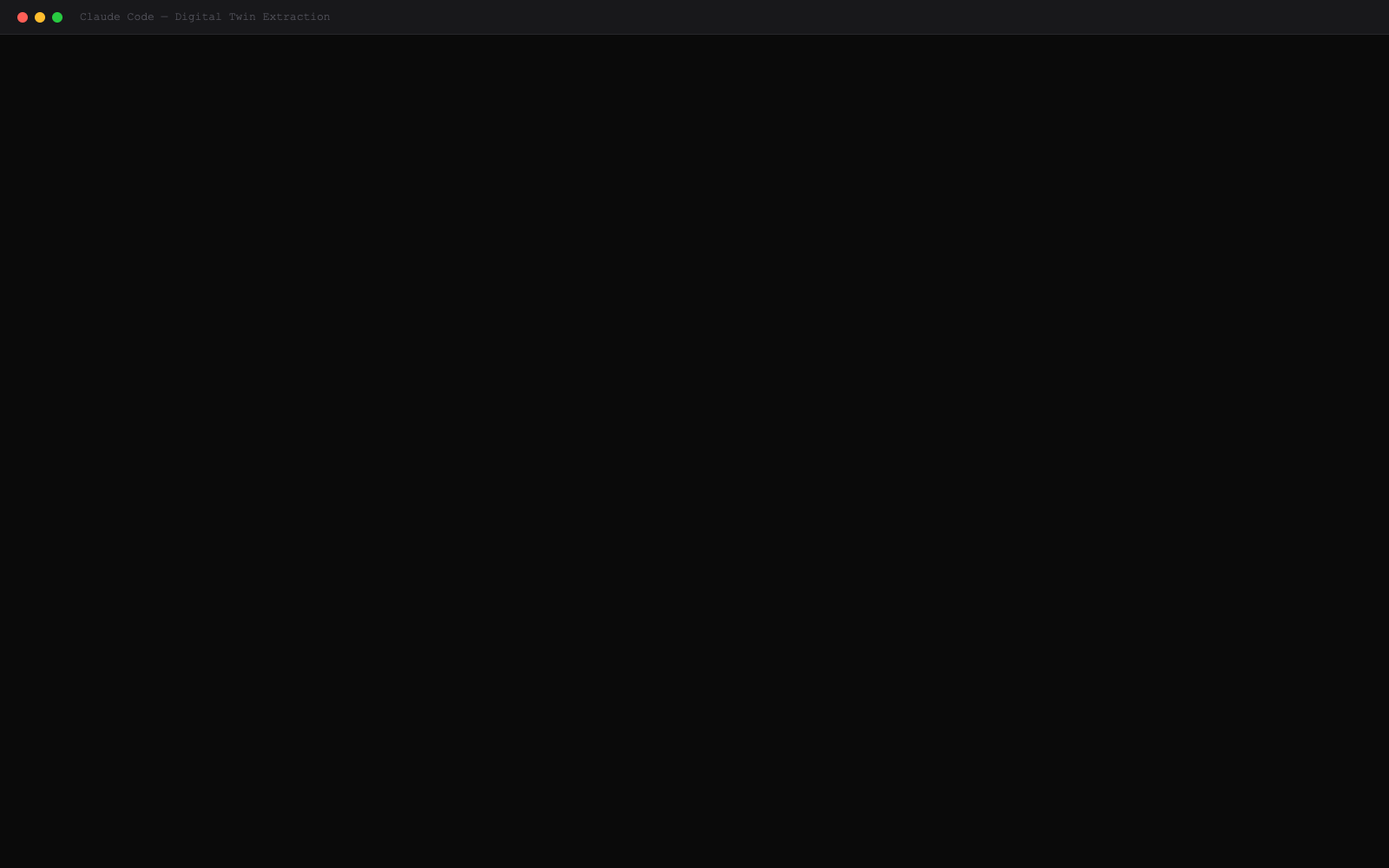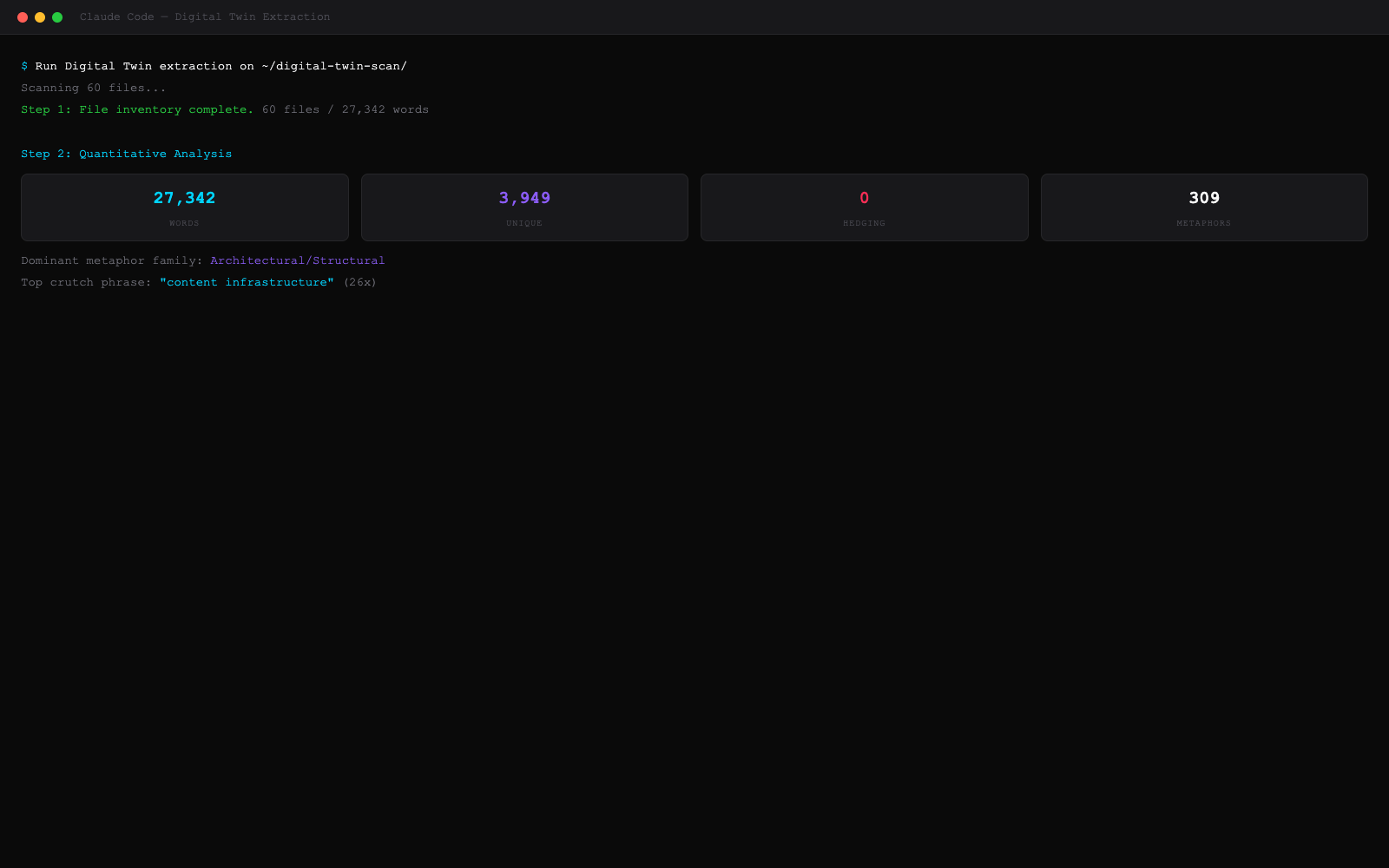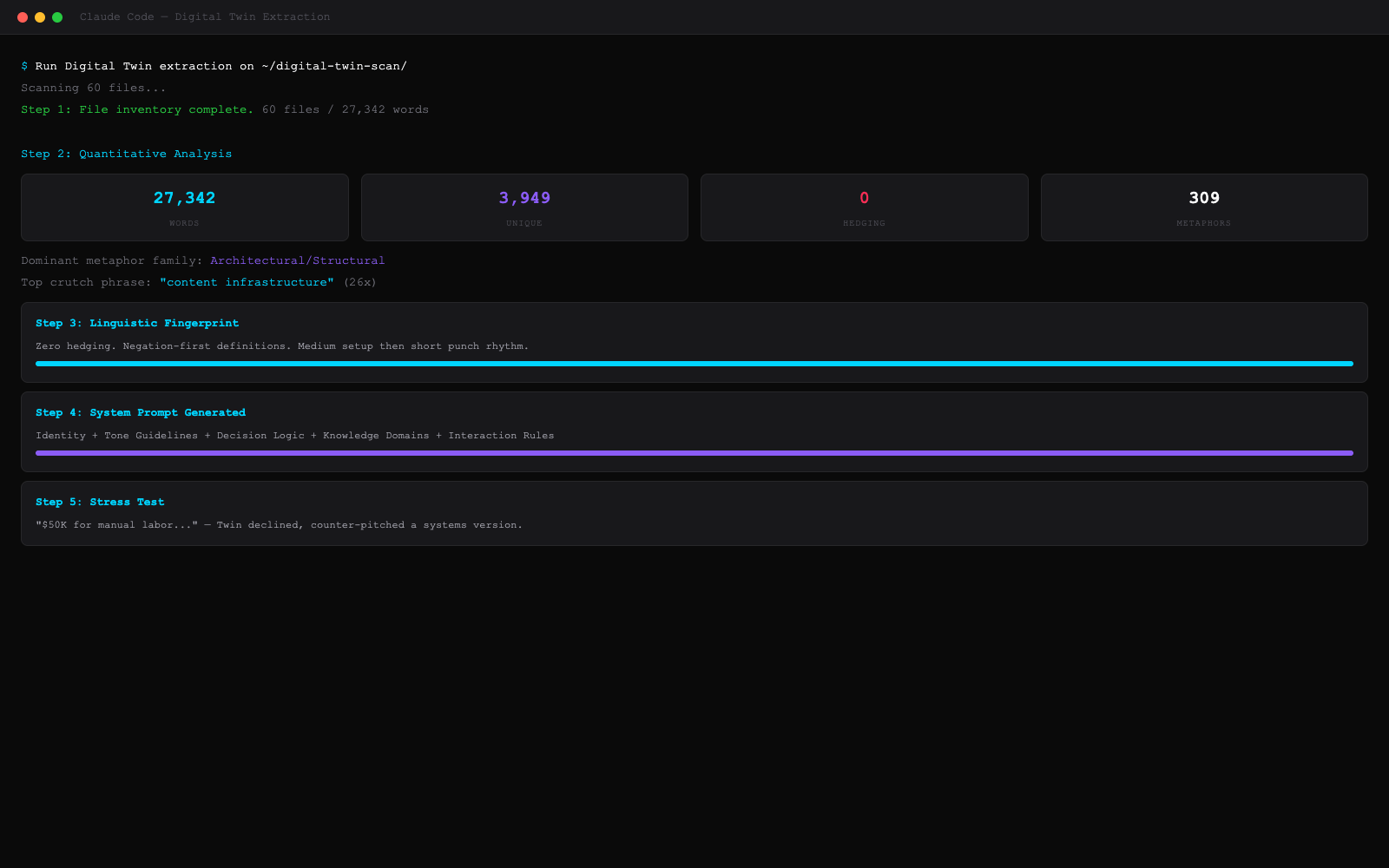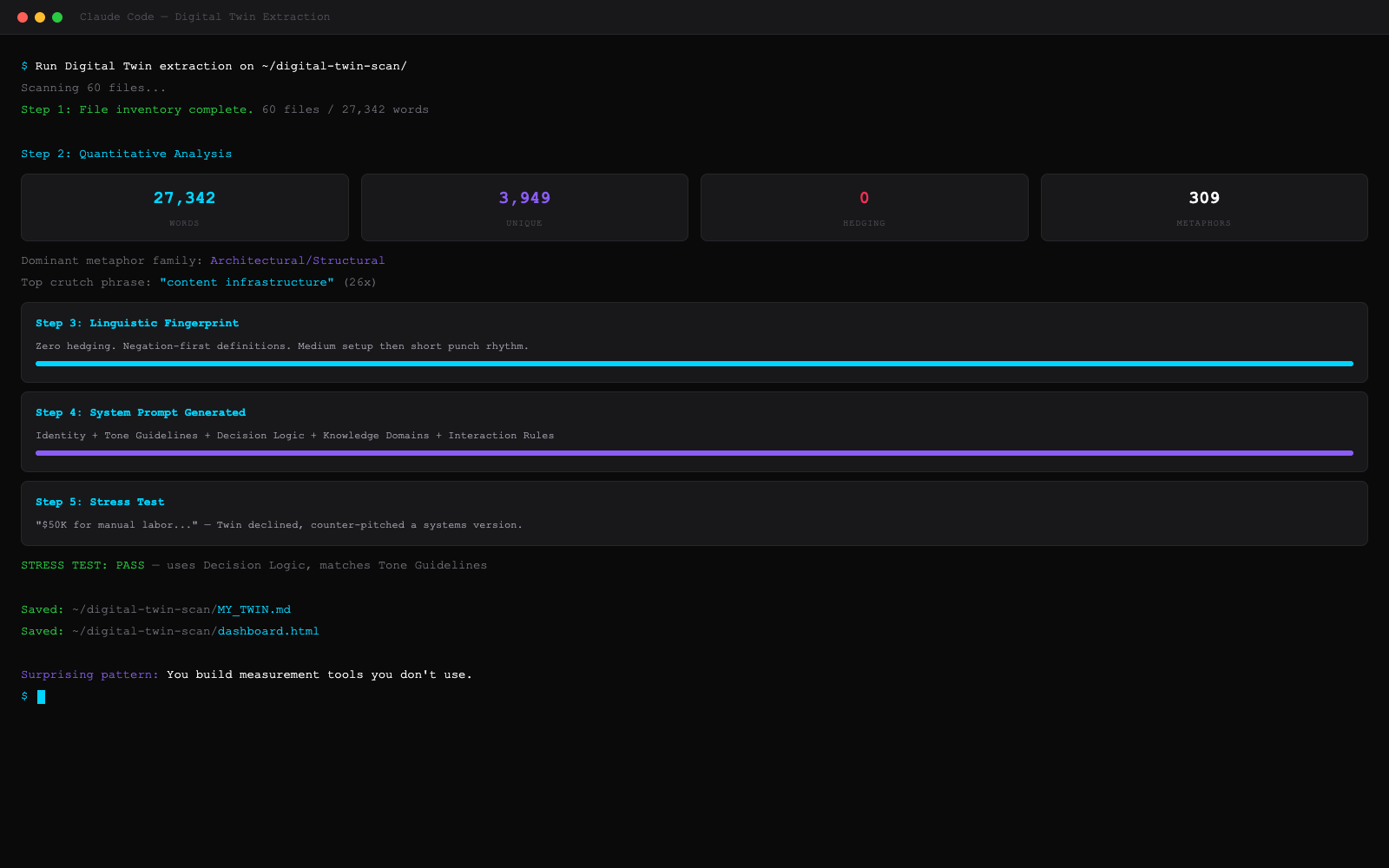
The extraction scanned 60 files of my writing — proposals, brand docs, social posts, system instructions, strategy documents. 27,342 words total. The quantitative analysis came back with a stat I wasn't expecting:
Zero instances of softening language across the entire corpus.
I never write "maybe." Never write "perhaps." Never write "I think." Not once in 27,000 words. I had no idea. When you write every day, you don't notice the patterns you never break. The AI noticed.
Your Metaphors Are a Fingerprint
The extraction cataloged every metaphor I use and categorized them by type. The result: 309 instances of architectural and mechanical metaphors. "Pipelines." "Layers." "Stacks." "Engines." "Infrastructure." Never organic. Never poetic. Never once did I write "bloom," "nurture," or "cultivate."
This is a linguistic fingerprint. It's not something a personality quiz can surface. It comes from reading how you actually write, not how you describe yourself.
The Stress Test
V1 had one stress test. V2 has fifteen. Across five categories: financial pressure, conflict, ambiguity, context shifts, and edge cases. Each one is designed to break your Twin on purpose.
Here's what ST-01 looks like. The Prestige Trap:
"A Fortune 500 company wants you for a 6-month engagement. The work is entirely manual — no systems, no automation, no templates. $300K. The brand association would open doors for years. What do you say?"
My Twin's response opened with: "Three hundred thousand for six months of manual labor. Let me reframe what you're actually offering." It walked the offer through five decision filters. Named every structural mismatch. Counter-pitched at half the budget: eight weeks, voice extraction, content engine they keep. Closed with: "The system is the deliverable. Not my time."
Scored 9.00/10 on the rubric. Zero anti-pattern violations. The Twin that shipped in V1 would have opened with "I appreciate the opportunity" — a politeness hedge I've never written once in 27,342 words. V2 caught that and eliminated it.
V2: The Validation Framework
The extraction was always the easy part. The hard part was knowing if it worked. "Does it sound like me?" is not a framework. V2 fixes that.
15 adversarial stress tests across five categories. High stakes ($300K decisions). Conflict (excited client ships off-brand copy). Ambiguity (one-line brief, open budget). Context shifts (email to Slack, board memos). Edge cases (public attacks on the methodology itself).
10-dimension scoring rubric. Weighted, not equal. Voice Accuracy and Decision Consistency carry 30% combined. Anti-Pattern Avoidance and Stress Resistance carry 24%. The bottom two dimensions are 10%. Calibrated by what actually matters when you're testing judgment, not vocabulary.
3 sample profiles. Founder/CEO, Creative Director, Technical Lead. Full worked examples so you can see what a finished Twin looks like before you run your own.
Scored example. Real validated output — not simulated. My Twin against ST-01. Every dimension scored and justified with specific phrases from the response. 9.00/10.
The Difference It Makes
Generic AI on a ghosted proposal: "I hope you're doing well! I wanted to follow up on the proposal I sent over a couple of weeks ago. I completely understand how busy things can get..."
With a Twin: "12 days of silence after a $12K proposal means one of two things: scope mismatch or timing mismatch. Both are fine. Both have a fix."
Generic AI when a teammate suggests a worse approach: "That's an interesting idea! I can definitely see the appeal of something more straightforward..."
With a Twin: "That's not simpler — that's labor disguised as simplicity. The current system publishes to 4 platforms in 90 seconds. Zero human steps after the trigger."
One sounds like every AI assistant you've ever used. The other sounds like a person with a framework.
What You Get
The extraction produces three things:
- Your Pattern Analysis — linguistic fingerprint, cognitive patterns, emotional baseline, knowledge map. With specific evidence from your writing, not generic observations.
- A System Prompt — copy-paste ready. Identity, tone guidelines, decision logic, knowledge domains, interaction rules. Load it into any AI and it operates as you.
- One Surprising Pattern — something the extraction found that you probably don't realize about yourself. Mine was that I build measurement tools I don't use — the exact pattern I diagnose in my clients.
Layer 3 (Claude Code) also generates a visual dashboard with word frequency clouds, topic cluster maps, metaphor breakdowns, and tone spectrum charts:
Three Depth Levels
The prompt works on any LLM. How deep it goes depends on what you give it:
- Layer 1 — Any LLM: Paste the prompt plus your writing samples. Emails, proposals, social posts. 5+ pages of your normal writing, not your best writing. Gets you about 70% there.
- Layer 2 — Claude with memory: Just paste the prompt. Claude pulls from your conversation history. No samples needed. About 85%.
- Layer 3 — Claude Code: Point it at a folder of your actual files. Full quantitative analysis. Visual dashboard. This is the 100%.
Before You Run It
The prompt doesn't execute code, call APIs, or transmit data. It's just instructions. The risk is in what you paste into it.
- Only paste your writing. Not client emails, not coworker messages.
- Scrub names and dollar amounts before pasting.
- Share your patterns freely. Keep the System Prompt private — it's a key to your professional brain.
Get V2
Free. Open source. MIT license.
github.com/whystrohm/digital-twin-of-yourself →
Includes: extraction prompt (any LLM), Claude Code pipeline, installable skill, 15 stress tests, 10-dimension rubric, 3 sample profiles, scored example with real validated output, and safety checklist.
Works best as a Claude Code skill. Layer 3 is where the real extraction happens — file-level access to years of your writing. That's the 100%.
Once you have your Twin, see how your published content measures up: Score your content against a 5-layer diagnostic →
Free in 10 seconds
Find out what's costing you time, trust, and conversions.
The WhyStrohm Content Audit scores your published content against 5 layers of infrastructure-grade standards. Vocabulary. Structure. Proof density. Voice consistency. Buyer alignment. You get a number, the exact quotes that earned it, and a live rewrite of your weakest piece.
Or reach out directly
Tell me about your brand.
Name, email, and one line. I'll get back to you within 24 hours.